Информация о процессах представлена в файле в виде таблицы.
В первом столбце таблицы указан идентификатор процесса (ID), во втором столбце таблицы – время его выполнения в миллисекундах, в третьем столбце перечислены с разделителем «;» ID процессов, от которых зависит данный процесс.
Если процесс независимый, то в таблице указано значение 0.
Определите максимальное количество процессов, которые могут быть завершены за первые 17 мс.
Считать, что каждый процесс начинается в самое раннее допустимое время.
Нумерация миллисекунд начинается с 1.
В файле содержится информация о совокупности N вычислительных процессов, которые могут выполняться параллельно или последовательно.
Приостановка выполнения процесса не допускается.
Будем говорить, что процесс B зависит от процесса A, если для выполнения процесса B необходимы результаты выполнения процесса A.
В этом случае процессы A и B могут выполняться только последовательно.
Информация о процессах представлена в файле в виде таблицы.
В первом столбце таблицы указан идентификатор процесса (ID), во втором столбце таблицы – время его выполнения в миллисекундах, в третьем столбце перечислены с разделителем «;» ID процессов, от которых зависит данный процесс.
Если процесс независимый, то в таблице указано значение 0.
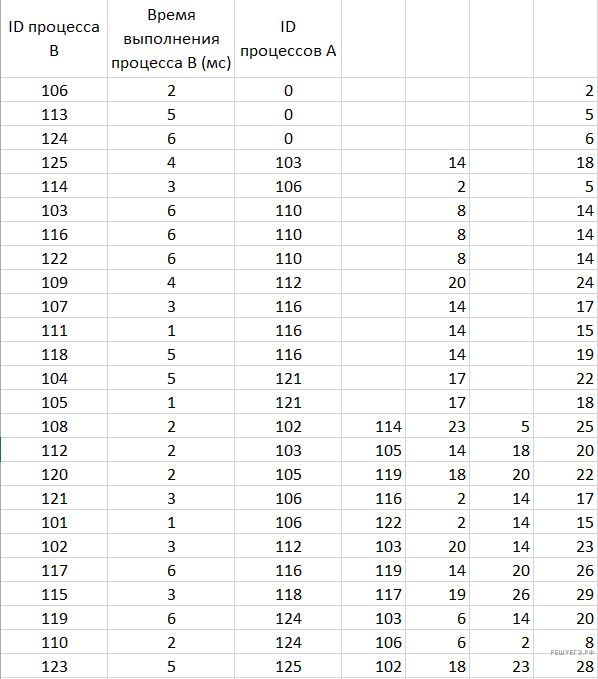
Выполните задания, используя данные из файла ниже:
Типовой пример организации данных в файле
ID процесса B
Время выполнения процесса B (мс)
ID процесса(-ов) A
1
3
0
2
4
1
3
2
2; 4
4
5
0
5
8
1; 4
6
3
1
Для приведённой таблицы процесс 3 начинается на 8-й мс и заканчивается на 9-й мс.
Типовой пример имеет иллюстративный характер.
Для выполнения задания используйте данные из прилагаемого файла.
Определите максимальное количество процессов, которые могут быть завершены за первые 17 мс.
Считать, что каждый процесс начинается в самое раннее допустимое время.
Нумерация миллисекунд начинается с 1.
Выполним сортировку данных по столбцу С .
Надо разделить данные в столбце «ID поставщиков данных» для тех процессов, где есть зависимость от двух процессов.
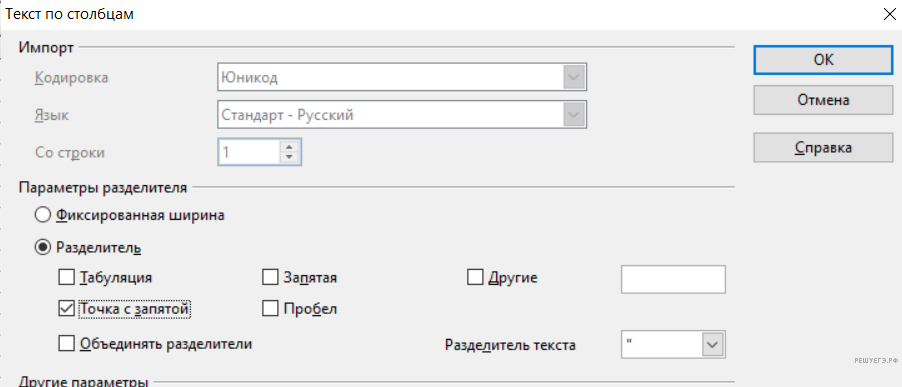
Для этого выделим столбец С , далее меню «Данные — Текст» по столбцам.
В меню мастера разделения текста по столбцам последовательно выберем «Формат данных с разделителями», далее «Символ разделитель: точка с запятой».
Формат данных столбца «Общий».
В OpenOffice аналогично:
В столбце G будем считать общее время выполнения процесса.
Для всех ячеек, у которых ячейка в столбце С равна нулю
Это значение будет равно значению в ячейке столбца В .
Запишем в ячейку G2 формулу =B2 и скопируем её на диапазон G2:G4.
В ячейку E5 запишем формулу =ВПР(C5;A:G;7;0) и скопируем ее на диапазон E5:E15 .
Данная формула выведет время процесса, от которого зависит текущий.
В ячейку G5 запишем формулу =E5+B5 , чтобы посчитать общее время выполнения процесса.
Скопируем формулу на диапазон G5:G15 .
В ячейку F16 запишем формулу =ВПР(D16;A:G;7;0) и скопируем ее на диапазон F16:F26 .
Данная формула выведет время второго процесса, от которого зависит текущий. В ячейку G16 запишем формулу
=МАКС(E16:F16)
+B16 , чтобы посчитать общее время выполнения процесса. Скопируем формулу на диапазон G16:G26 .
В столбце H будем выписывать время начала процесса, для этого в ячейку H2 введем формулу =G2-B2 и скопируем ее на диапазон H2:H26 .
Получаем таблицу:
Окончательно, воспользовавшись формулой
=СЧЁТЕСЛИ(G:G;"<18"), получим ответ — 12 .
Твой ИИ-помощник
Подсказки по заданию №22, без готовых формул.
Enter — отправить, Shift+Enter — новая строка.